
The AI industry is becoming more and more regulated, and an effective CI/CD platform can make a significant difference to an AI team's productivity. However, the variety of cloud platforms currently on the market makes it difficult to decide what is the right thing to do. This report provides a technical selection for infrastructure based on MLflow, Jenkins and AWS SageMaker, taking into account the replacement possibilities for teams at different times.
Job roles for the AI team
Most AI teams will probably have job roles as data scientists, data engineers, systems engineers, data analysts and so on. The designs referred to in this report are aimed at data scientists and engineers who already have some technical skills.
Design objectives
Cost first: it will eliminate all unnecessary overheads. Flexible: it does not limit the technical development of the team and the components can be replaced between open souce projects and AWS services. Efficient: it leverages existing cloud-native technologies as well as open source technologies.
Detailed architecture
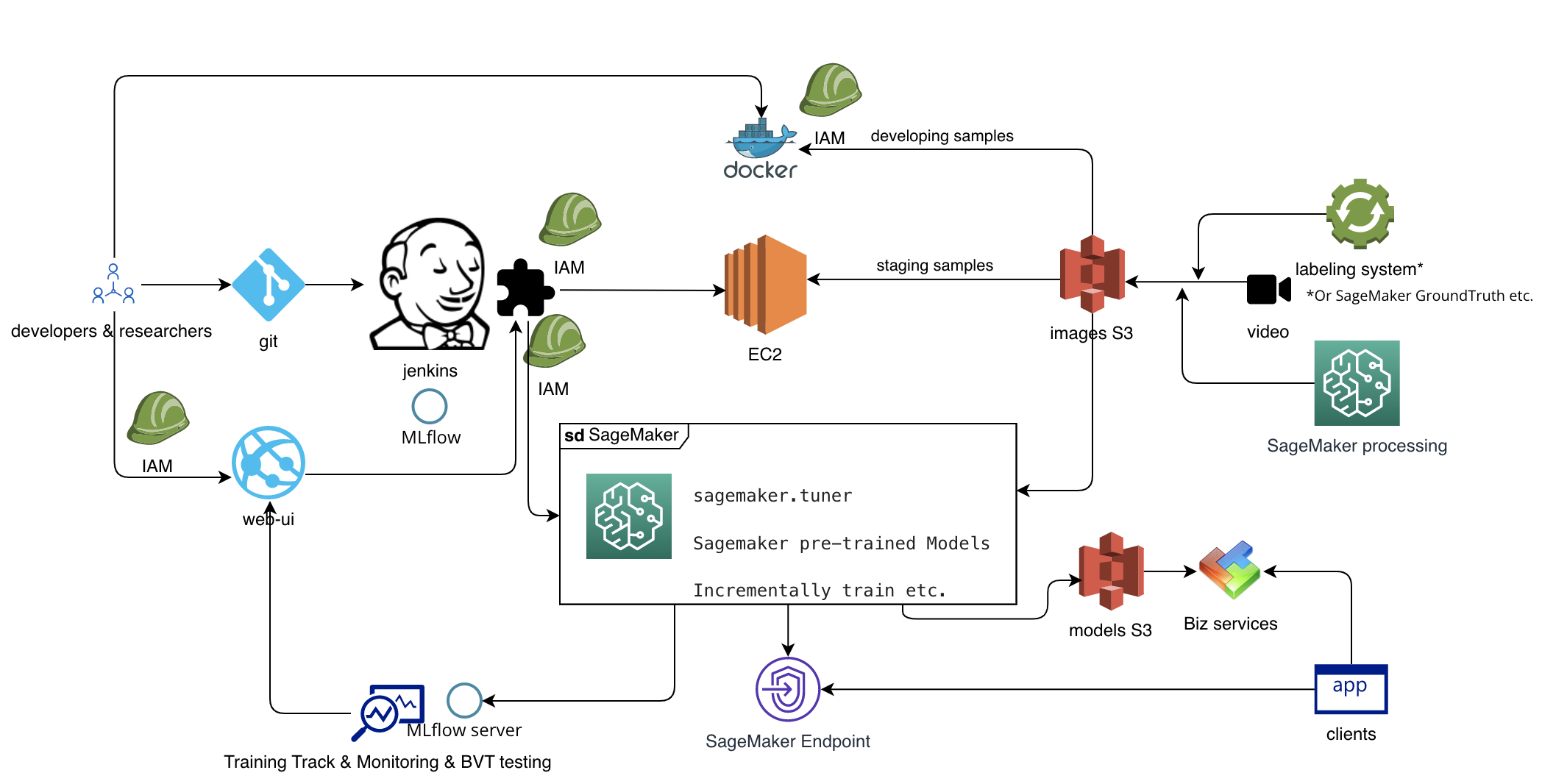
Phasing the work of an AI team
A machine learning or deep learning project can usually be divided into the following phases: data preparation, experiments, training the model, deploying the model online, and monitoring. This design focuses on the post data preparation phase.
Data preparation
At this stage, data cleansing is the main task. It is a good method to save the data in three different levels - development, test and production - so that it can be retrieved in a more differentiated manner to save costs. For example, if we can generate 1T of image files per day, it would be more convenient if we could save a sample of 1% or less of the data in another directory for development or testing. It can reduce the waste of resources in using the full amount of data for development.
In the architecture diagram above, this stage is depicted simply by the labeling system or by AWS SageMaker processing.
Experiments
This phase is primarily where the data scientist is tweaking the model and parameters to achieve the best results. What is critical at this stage is that the results of a large number of experiments need to be properly recorded in real time. The above design refers to MLflow, which is an open source machine learning lifecycle management platform. We can leverage MLflow's ability to perform metric logging of models as well as model saving. This avoids the situation where you forget to save the model with the best results during the experiment.
As a dedicated S3 directory is used at this stage (the data volume will not be too large), it is feasible to use MLflow directly to activate EC2 or even a local docker for experiments. MLflow here can also be replaced by the native capabilities of the SageMaker studio (SageMaker studio costs nothing to use it this way, but you have to launch other modules of SageMaker to have the tracking capabilities of MLflow).
Training
After the experiments have been passed, we often use the full amount of data, or through some online incremental approach to train models. The use of resources is greatest at this stage. Refined management at this stage is key to cost control.
The Staging environment is well used by some teams and they hardly used local environments. Other teams barely use the Staging environment. This relies on the complexity of the business. The more complex the business, the more difficult it is to do the whole environment directly locally. In some big teams, everyone crams into a Staging that is very close to the online environment. Whether you use the Staging environment or not, it makes sense to have a dataset for this environment that is halfway between the development and production environments.
At this stage we introduced Jenkins to achieve CI (the replacement option is AWS codepipeline). When the specified branch of code is committed, Jenkins tasks are executed, in which again the main execution is MLflow to control EC2 or SageMaker for training. The points in the training code can be output or monitored in two forms, a log from MLflow and a log from AWS LogWatch (one almost free, one for a fee). At the same time, if the budget is large enough, the more versatile features of SageMaker can be used as well, such as the numerous pre-trained models.
Deployment
The models under training are mainly stored temporarily in MLflow. The trained models can be placed in S3 or sent to a SageMaker endpoint to provide http services. Before these deployments can be triggered, they need to pass an A/B test. The mechanism is reached through Jenkins' workflow. By using the project compilation template, if the model completed in the previous step fails the automated test, or if a score such as AUC falls below a certain value, the deployment operation will be paused in the Jenkins workflow. Teams with approval requirements can also add an approval process here. Meanwhile, the corresponding fee-based solution is AWS codepipleline, which can also be configured out for approval deployments and is also naturally scalable horizontally. however, it doesn't cost as little as its official website states.
Monitoring
The monitoring phase includes monitoring and alarming of the production environment as well as data monitoring during the experiments phase. Production environments need SMS or email alerts. AWS Logwatch is a good option. If you have an existing Ops system, it's also good to add it. And for experiments environments, MLflow is perfectly suited to the task.
Summarise
A diagram to summarise the options that can be used in the various stages. The rest of how to assemble them requires a lot of detailed coding work, which is IaC work.
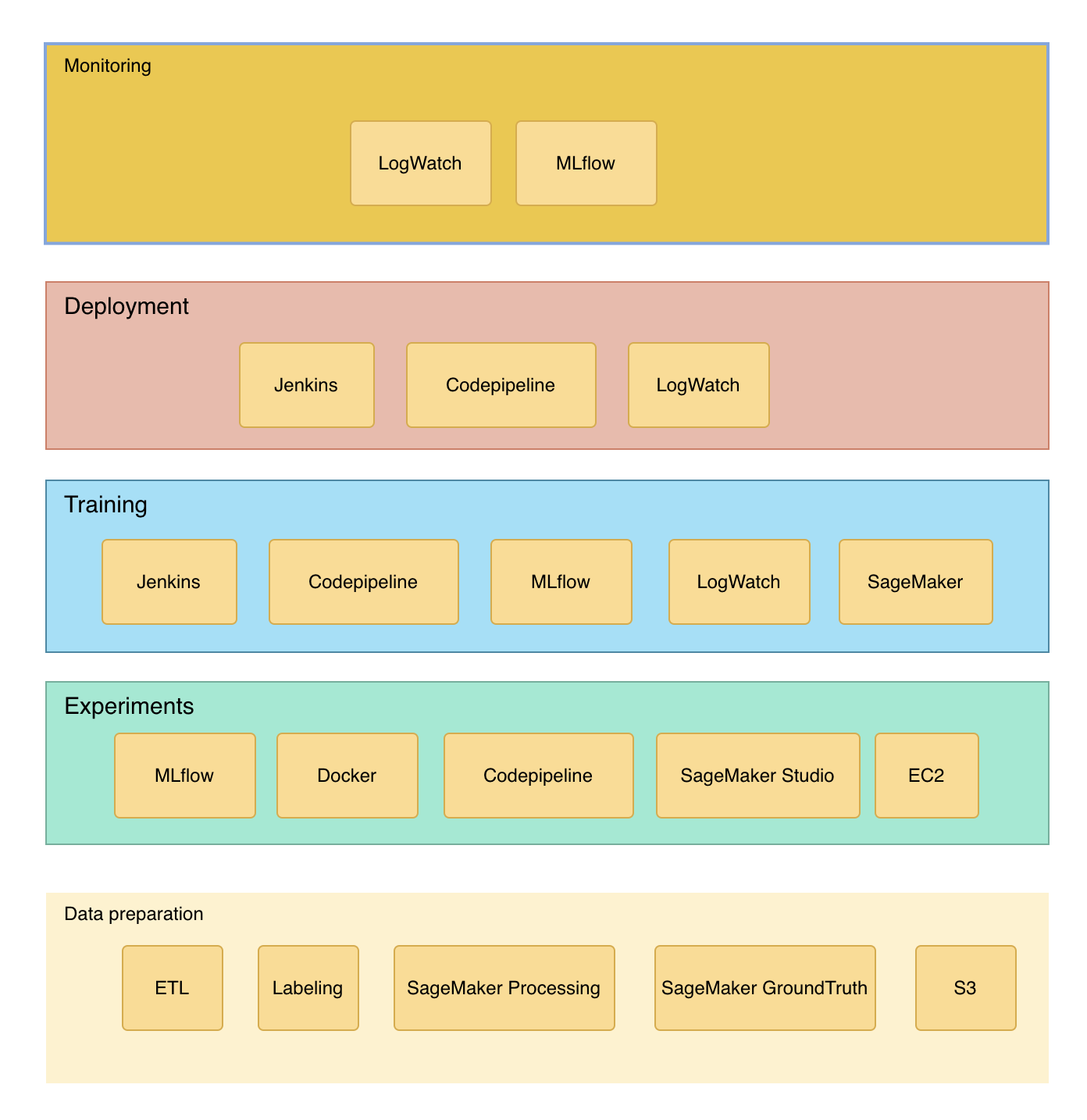
The advantage of this design is that it is possible to have all components as open source projects or all AWS components, with the flexibility to switch depending on team size and budget. The disadvantage is that there is still a lot of IaC coding work to be done to make it really work. Also this was a summer internship program at Google.
References
https://docs.aws.amazon.com/codepipeline/latest/userguide/approvals-action-add.html
https://www.techtarget.com/searchaws/tip/Compare-AWS-CodePipeline-vs-Jenkins-for-CI-CD
https://aws.amazon.com/codepipeline/pricing/
https://www.youtube.com/watch?v=jpZSp9O8_ew
https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-notebooks-instances.html
https://docs.aws.amazon.com/sagemaker/latest/dg/docker-containers.html
https://aws.amazon.com/getting-started/hands-on/machine-learning-tutorial-build-model-locally/
https://github.com/awslabs/sagemaker-defect-detection
https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-projects-whatis.html
https://www.jenkins.io/projects/gsoc/2020/project-ideas/machine-learning/