
Facebook史上最严重宕机,全网宕机七小时,高管道歉,股价下跌。不过还好,对我们影响不大。
文章来源于cloudflare的技术博客 https://blog.cloudflare.com/october-2021-facebook-outage/
"Facebook不可能宕机,对不?",我们考虑了3秒。
在今天UTC时间16:51,我们打开了一条内部故障名为“Facebook DNS 回环返回失败”,因为我们担心我们自己的1.1.1.1的DNS服务有啥异常。但当我们打算发到公开状态页里时,我们意识到还有更严重的事情要发生。
社交媒体迅速火了起来,报道着我们发现的事情。实际上,Facebook和他旗下的Whatsapp和Instagram全都挂了。他们的DNS域名停止了解析,并且他们的基础架构的ip也不能访问了。就好像是有人在他们的数据中心内部一下子拔了电源,切断了与互联网的连接。
这怎么可能呢?
初识BGP
BGP是Border Gateway Protocol的缩写。它是在Internet AS之间交换路由信息的一种机制。使互联网正常工作的大型路由器有大量不断更新的可能路由列表,用于将每个网络数据包发送到最终目的地。没有BGP,互联网路由器就不知道该做什么,互联网也就无法工作。
互联网实际上是由多个网络组在一起的网,通过BGP组在一起的。BGP允许一个网络(比如Facebook)向其他组成互联网的网络发布自己的存在。在我们写这篇文章的时候,Facebook并没有宣传自己的存在,isp和其他网络无法找到Facebook的网络,所以它是不可用的。
每个独立的网络都有一个ASN号。AS (Autonomous System)是一个内部具有统一路由策略的独立网络。AS可以产生前缀(假设它们控制一组IP地址),也可以传输前缀(假设它们知道如何到达特定的IP地址组)。
Cloudflare的ASN是AS13335。每个ASN节点需要通过BGP向Internet发布其前缀路由;否则,没人知道如何连接,也没人知道在哪里能找到我们。
我们的学习中心对BGP和ASNs是什么以及它们是如何工作的有很好的概述。
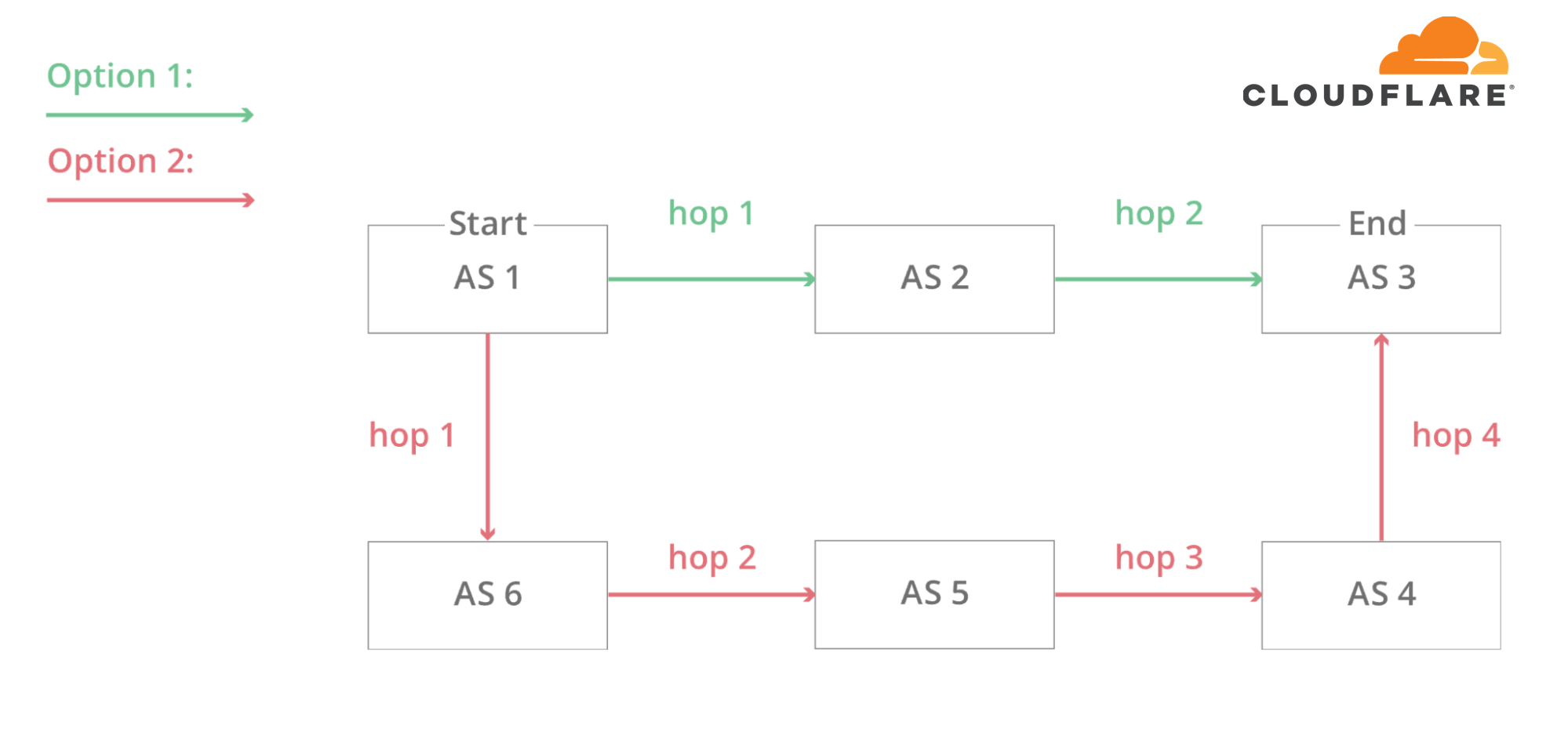
在这个简化的图表中,您可以看到互联网上的六个自治系统和两个可能的路径,一个包可以沿着从头到尾使用。AS1→AS2→AS3是最快的,AS1→AS6→AS5→AS4→AS3是最慢的,但是如果第一个失败了,可以使用这个慢的。
在16:58 UTC时,我们注意到Facebook已经停止向他们的DNS前缀发路由了。意味着,那会至少DNS是不能用了。所以,Cloudflare的1.1.1.1的DNS无法再回应有关facebook.com或者instagram.com的解析查询了。
route-views>show ip bgp 185.89.218.0/23
% Network not in table
route-views>
route-views>show ip bgp 129.134.30.0/23
% Network not in table
route-views>
与此同时,Facebook的其他IP地址仍然保持路由,但并不是特别有用,因为没有DNS,Facebook和相关服务实际上不可用:
route-views>show ip bgp 129.134.30.0
BGP routing table entry for 129.134.0.0/17, version 1025798334
Paths: (24 available, best #14, table default)
Not advertised to any peer
Refresh Epoch 2
3303 6453 32934
217.192.89.50 from 217.192.89.50 (138.187.128.158)
Origin IGP, localpref 100, valid, external
Community: 3303:1004 3303:1006 3303:3075 6453:3000 6453:3400 6453:3402
path 7FE1408ED9C8 RPKI State not found
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
route-views>
我们跟踪我们在全球网络中看到的所有BGP更新和公告。在我们的能力范围,我们收集的数据让我们了解到互联网是如何连接的,以及流量将从哪里流向地球上的任何地方。
BGP UPDATE消息会通知路由器你对前缀发布的任何更改,或者完全撤销该前缀。我们可以清楚的看到这点,特别是在检查我们的时间序列的BGP数据库时,我们收到了来自Facebook的更新。通常情况下,这个图表是相当安静的:Facebook不会每分钟都对其网络做出太多改变。
但在UTC时间15:40左右,我们看到Facebook的路由变化达到峰值。麻烦就是从那时开始的。
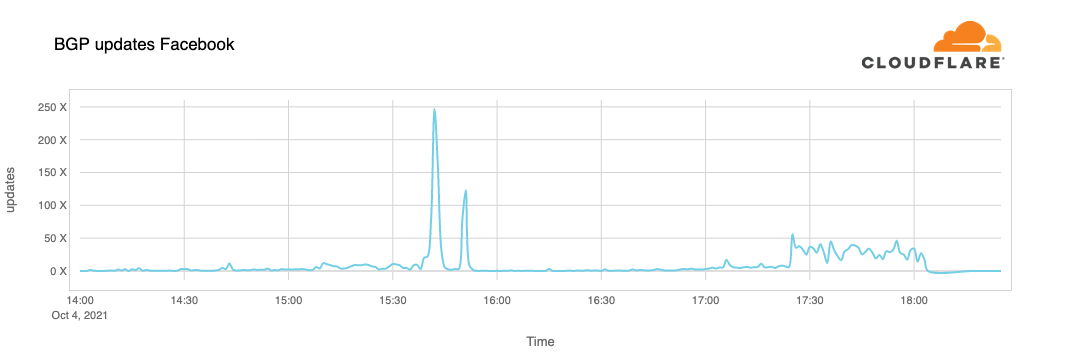
如果我们把这个视图按路由通告和路由回收分开,我们就能更好理解发生了什么。路由被回收,Facebook的DNS服务器下线,问题发生一分钟后,Cloudflare的工程师在一个屋子里想知道为啥1.1.1.1不能解析facebook了,并担心是不是自己有啥故障了。

这一堆回收之后,Facebook和他的其他产品有效地从互联网上断开了。
DNS产生影响
直接的后果是,全世界的DNS解析器都停止解析他们的域名。
➜ ~ dig @1.1.1.1 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @1.1.1.1 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN A
➜ ~ dig @8.8.8.8 facebook.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;facebook.com. IN A
➜ ~ dig @8.8.8.8 whatsapp.com
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 31322
;whatsapp.com. IN A
之所以会出现这种情况,是因为与Internet上的许多其他系统一样,DNS也有自己的路由机制。当有人在浏览器中输入https://facebook.com URL时,负责将域名翻译成实际连接的IP地址的DNS解析器首先检查缓存中是否有内容并使用它。如果没有,它会尝试从域名服务器获取答案,这些域名服务器通常由拥有它的实体托管。如果无法访问名称服务器或由于其他原因而无法响应,则返回一个SERVFAIL,浏览器向用户发出一个错误。同样,我们的学习中心对DNS的工作原理提供了很好的解释。
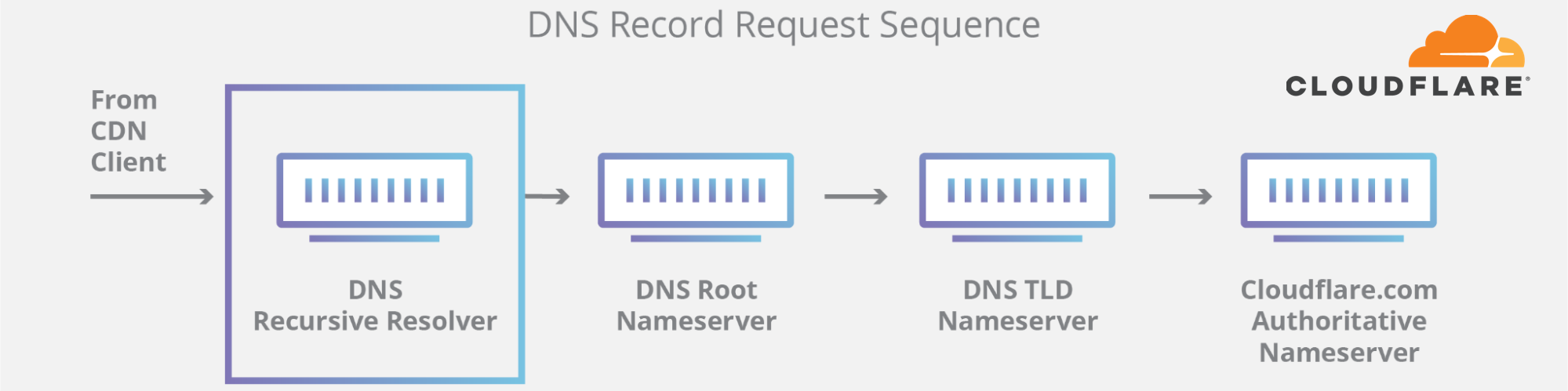
由于Facebook停止通过BGP宣布他们的DNS前缀路由,我们和其他人的DNS解析器无法连接到他们的域名服务器。因此,1.1.1.1、8.8.8.8和其他主要的公共DNS解析器开始发出(和缓存)SERVFAIL响应。
但这还不是全部。现在,人类行为和应用逻辑开始发挥作用,导致另一个指数效应。随之而来的是更多DNS流量的海啸。
发生这种情况的部分原因是,应用程序不会接受一个错误的答案,并开始重新尝试,有时是激进的,部分原因是终端用户也不会接受一个错误的答案,并开始重新加载页面,或关闭并重新启动他们的应用程序,有时也是激进的。
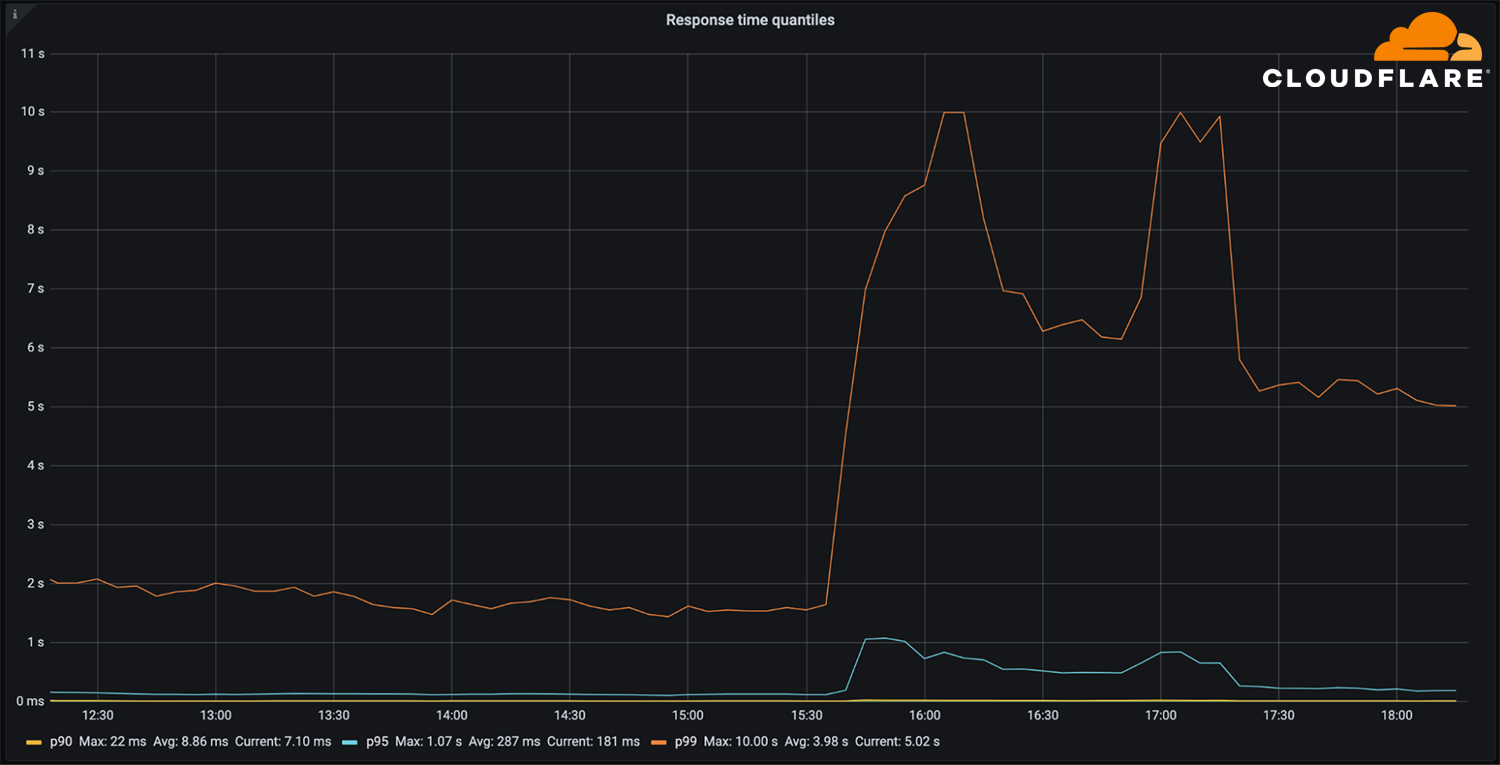
这是我们在1.1.1.1上看到的流量增长(请求数量):
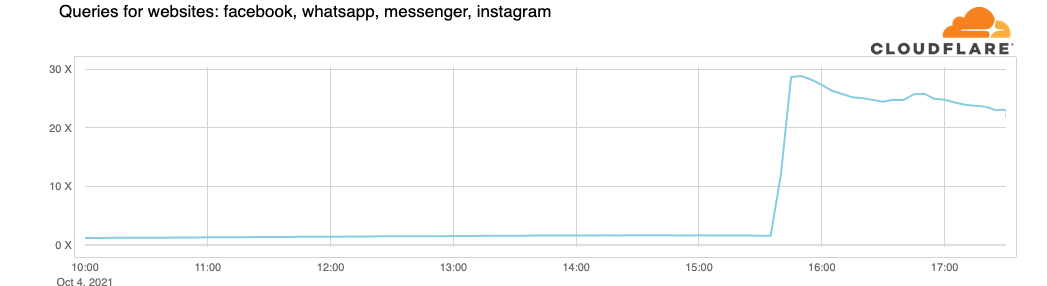
所以现在,因为Facebook和他们的网站太大了,我们的DNS解析处理的查询比平时多30倍,这可能会给其他平台带来延迟和超时问题。
幸运的是,1.1.1.1是免费的、私有的、快速的(作为独立的DNS监控器DNSPerf可以证明),并且是可扩展的,我们能够以最小的影响为用户提供服务。
我们绝大多数的DNS请求都在10毫秒内解决。与此同时,极小部分的p95和p99百分比看到了响应时间的增加,可能是由于过期的ttl不得不求助于Facebook名称服务器和超时。10秒DNS超时限制在工程师中是众所周知的。
影响其他服务
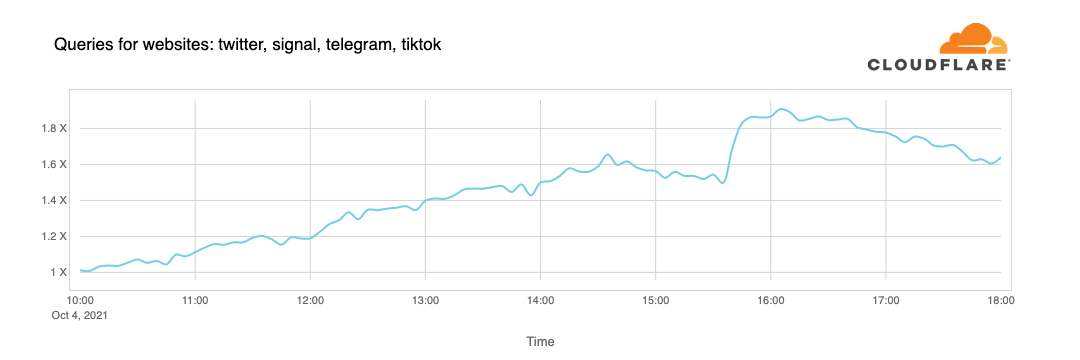
人们在寻找其他选择,想知道更多或讨论咋的了。当Facebook变得无法访问时,我们开始看到对Twitter、Signal和其他消息和社交媒体平台的DNS查询增加了。
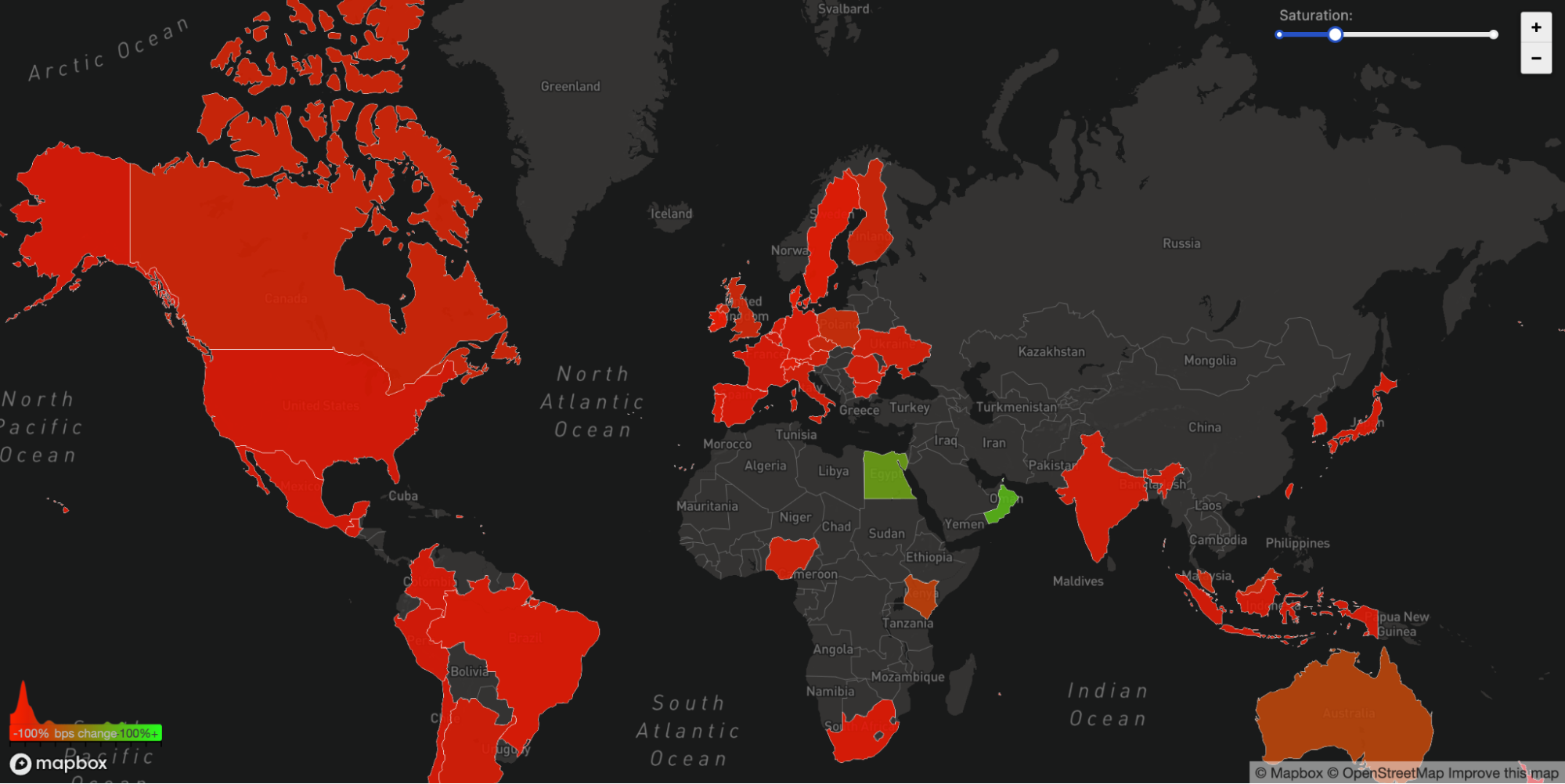
我们还可以从Facebook受影响的ASN 32934的WARP流量中看到这种不可达性的另一个副作用。这个图表显示了在UTC时间15:45到16:45之间,每个国家的流量与三小时前相比的变化情况。在世界范围内,来往于Facebook网络的WARP流量完全消失了。
互联网
今天的事件提醒我们,互联网是一个由数百万个系统和协议共同工作的非常复杂和相互依赖的系统。实体之间的信任、标准化和合作是它为全球近50亿活跃用户服务的核心。
更新
在UTC时间21:00左右,我们看到Facebook的BGP活动在UTC时间21:17达到顶峰。

该图表显示了Cloudflare的DNS 1.1.1.1上DNS名称“facebook.com”的可用性。它在UTC时间15:50左右停止可用,并在UTC时间21:20返回。
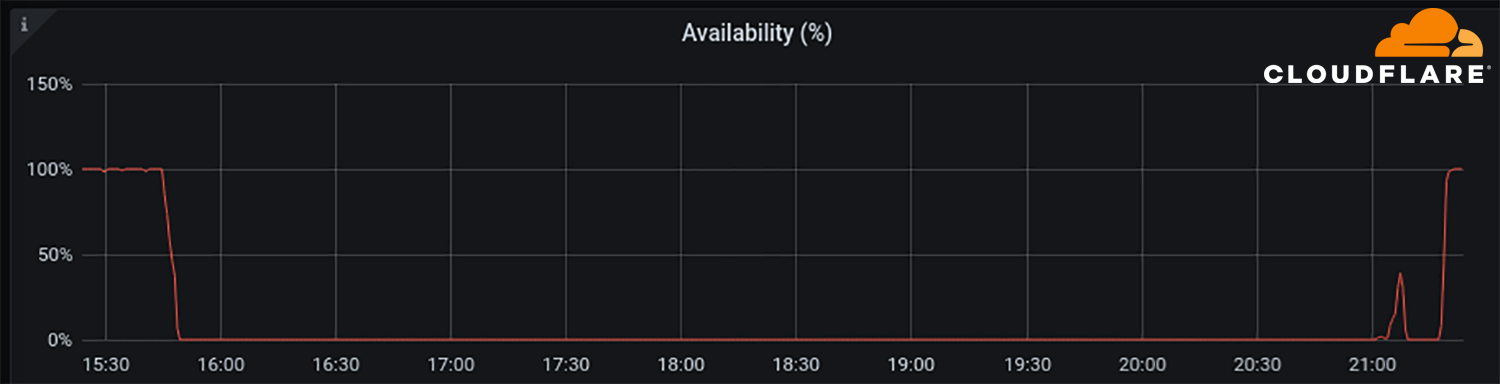
毫无疑问,Facebook、WhatsApp和Instagram的服务将需要更长的时间才能上线,但在UTC时间21点28分,Facebook似乎已重新连接到全球互联网,DNS也再次工作。