
AI行业的发展越来越规范,一套有效的CI/CD平台,可以让一个AI团队的工作效率大幅提升。但当前市场上五花八门的云平台让人难以决择,究竟如何做才是正确的,本文以MLflow,Jenkins和AWS SageMaker为基础,兼顾不同时期的团队的替换可能性,为基础架构提供技术选型。
AI团队的工作角色
大多数AI团队的工作角色可能会有数据科学家,数据工程师,系统工程师,数据分析师等等,本文所提到的设计更倾向于已经拥有一定技术能力的数据科学家和工程师。
设计目标
成本第一,省去一切不必要的开销。灵活,不限制团队的技术发展,可在任意位置上用相应的技术进行替换。高效,充分利用现有的云原生技术以及开源技术。
详细架构图
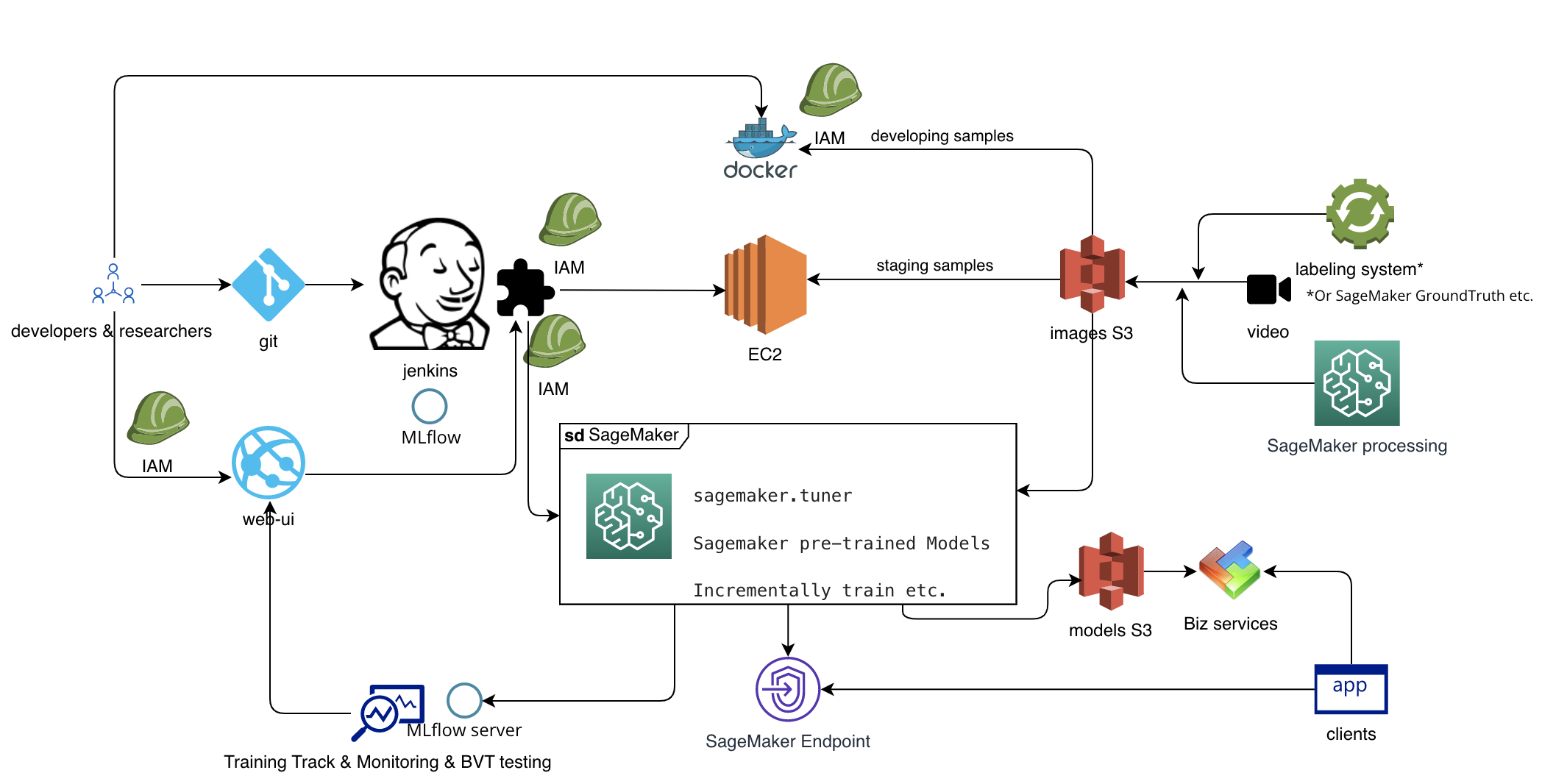
AI团队的工作阶段划分
一个机器学习或者深度学习的项目,通常可以分为以下几个阶段:数据准备,实验,训练模型,上线模型,监控。本设计主要关注在数据准备后的阶段。
数据准备
在这个阶段,数据清洗是最主要的工作。将清洗完成的数据靠人工或者机器打上标签,并按照一定的规范保存到S3。这一阶段要注意的是,保存的数据最好以开发,测试,线上三个环境进行不同数量级的保存,这样使得取数据的时候更加有区分以节省成本。比如说,如果我们每天能够产生1T的图片文件,那么如果能够同时抽样保存1%的数据或者更少到另一个目录供大家开发或者测试时使用,将更加便利。同时也降低了全量使用数据进行开发的资源浪费。
在上述的架构图中,这个阶段被简单地以标签系统或者AWS的SageMaker processing所描述。
模型实验
这阶段主要是数据科学家在调整模型和参数,以取得最佳的结果。这阶段最关键的是大量的实验结果需要被实时适当的记录。上述设计中提到了MLflow,它是一个开源的机器学习生命周期管理平台。我们可以借助MLflow的能力,进行模型的指标打点以及临时的模型保存。这让很多来不及保存的过程得以记录。
因为这个阶段是使用了专用的S3目录(数据量不会太大),直接使用MLflow激活EC2甚至是本地的docker做实验是可行的。这里的MLflow也可以使用SageMaker studio的本地能力(这样使用是不要钱的,但没有MLflow的跟踪能力)。
全量训练
在实验通过后,我们常常会使用全量数据,或者通过一些线上的增量办法来进行模型的训练,此时对资源的占用是最大的,在此阶段的精细化管理是成本控制的关键。
Staging环境在一些业务团队中被用得很好,而本地环境几乎不用。而另一些团队几乎不用Staging环境。这依赖于业务的复杂度,越复杂的业务,越难在本地直接完成整体环境,于是大家都挤到一个非常接近线上环境的Staging中。不论大家是否使用Staging环境,为此环境准备一份介于开发和生产环境中间的数据集,是有意义的。
在这阶段我们引入了Jenkins来达到CI的效果(可选方案还有AWS codepipeline)。当指定的代码分支被提交时,Jenkins的任务被执行,在其中又主要是执行MLflow来控制EC2或者SageMaker进行训练。 训练代码中埋的点,可以按照两种形式进行输出或者监控,一个是MLflow的log,另一个是aws logwatch的log(一个几乎免费,一个收费)。与此同时,如果预算够多,SageMaker的更多功能也是合适的,例如众多的预训练模型。
部署
训练中的模型主要在MLflow中临时保存。训练好的模型可以放到S3中或者发到SageMaker endpoint中去提供http服务。触发这些部署前,需要通过A/B test,这项机制通过Jenkins的工作流来达到。使用项目编译模板,如果在上一步中完成的模型无法通过自动化测试,或者auc等打分低于某个值,则在Jenkins的工作流中截断部署操作。有审批要求的团队,也可以在此处增加审批过程。同时,对应的收费方案为AWS的codepipleline,它同样也可以配置出来审批部署等,而且也天然可以横向扩展,但是价格并不像官网所宣传的一样实惠。
监控
监控阶段包括了生产环境的监控和报警以及实验阶段的数据监控。生产环境需要短信或者邮件报警,AWS Logwatch是个不错的选项。如果有已经存在的运维系统,对接上代码打点也是不错的。而针对实验环境,MLflow完全能够胜任,大量的过程数据将会被其记录下来。
总结
用一张图来总结一下,在各环节里可以采用的方案。剩下如何组装对接,还需要大量的细节编码工作,不过都还好,全部是IaC的工作。
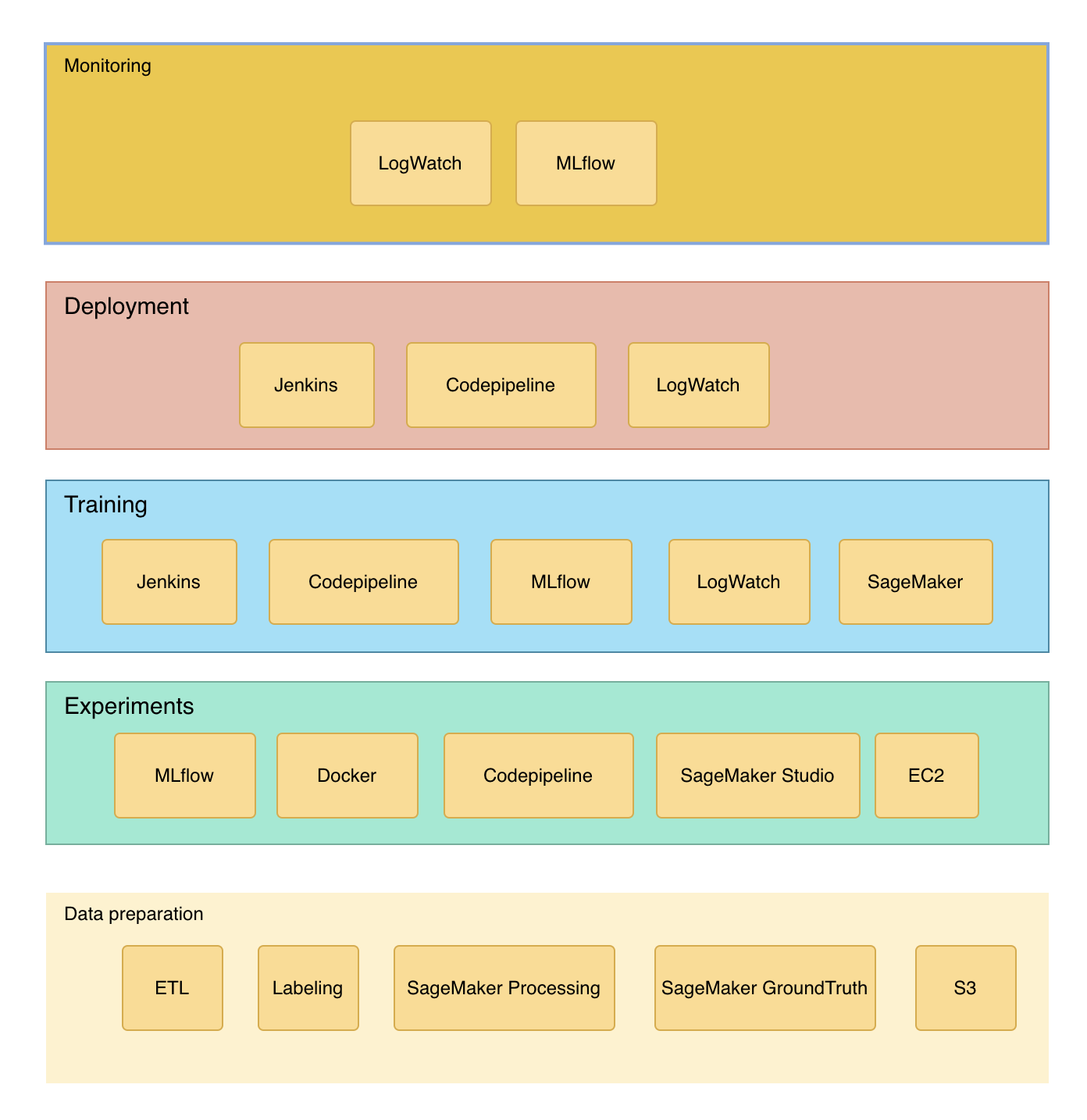
本设计的优点在于,可以全部组件都是开源项目,也可以全部是AWS组件,根据团队规模和预算灵活切换。缺点在于,还需要大量的IaC编码工作,才能真正工作。同时这也是Google的一次夏季实习项目。
引用
https://docs.aws.amazon.com/codepipeline/latest/userguide/approvals-action-add.html
https://www.techtarget.com/searchaws/tip/Compare-AWS-CodePipeline-vs-Jenkins-for-CI-CD
https://aws.amazon.com/codepipeline/pricing/
https://www.youtube.com/watch?v=jpZSp9O8_ew
https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-notebooks-instances.html
https://docs.aws.amazon.com/sagemaker/latest/dg/docker-containers.html
https://aws.amazon.com/getting-started/hands-on/machine-learning-tutorial-build-model-locally/
https://github.com/awslabs/sagemaker-defect-detection
https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-projects-whatis.html
https://www.jenkins.io/projects/gsoc/2020/project-ideas/machine-learning/